
 Departamento de Conservación y Recreación (DCR)
Departamento de Conservación y Recreación (DCR) Conservar. Proteger. Disfrutar.
Departamento de Conservación y Recreación (DCR) 




 Tabla de contenidos
Tabla de contenidosEsta sección proporciona una introducción a los procedimientos que emplea el DCR-DNH en la recopilación de datos de campo y el desarrollo de clasificaciones de comunidades ecológicas.
Recogida de datos
Los ecologistas del DCR-DNH están comprometidos con un enfoque cuantitativo para el muestreo, análisis y clasificación de la vegetación utilizando protocolos estándar de muestreo de campo y métodos numéricos de análisis de datos. Este énfasis es consistente tanto con una larga historia de investigaciones de vegetación en América del Norte y Europa como con los estándares nacionales de los Estados Unidos para la clasificación de la vegetación (Jennings et al. 2009; Peet et al. 2012). Los datos cuantitativos identifican explícitamente las diferencias en abundancia y biomasa entre las especies de plantas que coexisten. Los datos recopilados a partir de unidades de muestra de tamaño estándar conocido proporcionan una base coherente para comparar rodales de vegetación dispar y facilitan el intercambio de datos entre los usuarios en una medida que no es posible con meras listas de especies o datos recopilados en un área de tamaño indefinido. Los patrones en la composición y estructura de las comunidades ecológicas dependen de la escala de observación, y un protocolo de muestreo que especifica una escala particular reduce tanto la probabilidad de patrones de oscurecimiento en múltiples escalas como el sesgo del muestreador para determinar si se registran especies particulares. Del mismo modo, los métodos numéricos de análisis ofrecen medios objetivos para generar y evaluar una clasificación de la vegetación y permiten la detección de patrones que de otro modo podrían permanecer inaparentes. La recopilación y el análisis de datos cuantitativos para apoyar la clasificación ecológica no deben considerarse ni como panaceas ni como fines en sí mismos. Más bien, son importantes como herramientas para promover la conservación de la biodiversidad, pero proporcionan un objetivo crítico, un contexto científico para hacerlo.
Data collection follows standard protocols developed and refined by DCR-DNH over the past 25 years. The fundamental components of these protocols are consistent with sampling techniques employed by other state Natural Heritage programs a wide range of other users (e.g., Peet et al. 1998). For inventory purposes and most contract projects, data are collected from plots 400 m2 in forests and woodlands and 100 m2 in shrubland and herbaceous vegetation. On natural area preserves and other managed areas that require permanently marked plots for long-term monitoring, modular plots up to 1000 m2 that contain nested subplots are sampled more intensively to provide information about vegetation structure, composition, and species richness at multiple spatial scales. In all cases, within each plot all vascular plants present are recorded and the total individual cover of each taxon (defined as the vertical projection of all above-ground biomass) is estimated and assigned to one of nine cover classes representing a range of percentage values. Vegetation structure is assessed by estimating the cover of each woody species at six vertical (height) strata, and stem diameters are measured for all woody stems => 2.5 cm at breast height (1.4 m). A standard set of environmental data is collected, including elevation, aspect, degree of slope, coverage of different types of surface substrate, soil characteristics, and qualitative measures of soil moisture and hydrology. A soil sample is routinely collected from each plot in order to document soil chemistry. All sampling locations are recorded using a global positioning system (GPS). The sampling protocol can include photographic documentation and cursory examination of tree increment cores to deduce stand age and history. Click here for a copy of the DCR-DNH standard plot data collection field form and Instructions (requires the free Adobe reader).
Análisis y clasificación de datos
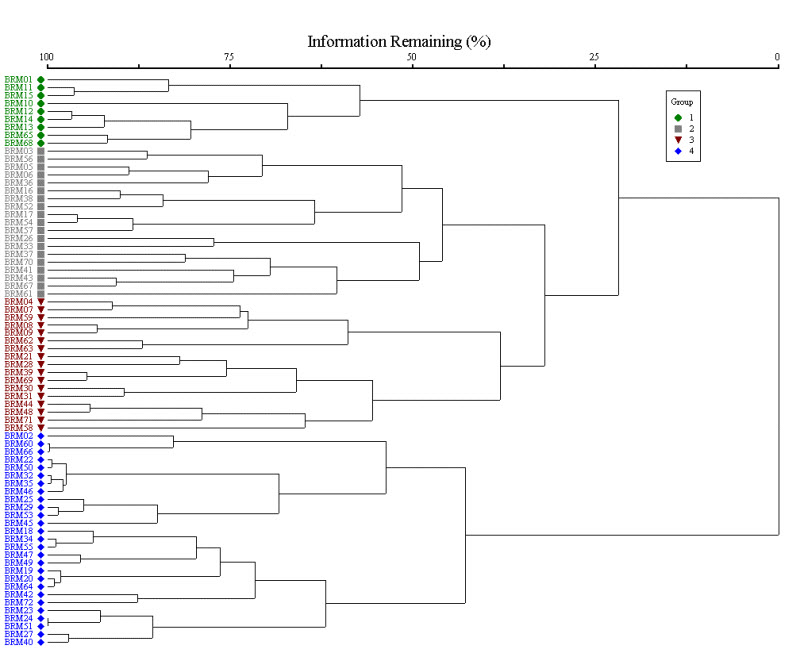
Se emplean métodos numéricos para generar clasificaciones, y se ha puesto énfasis en circunscribir unidades en todo su rango de distribución en Virginia y regionalmente. Adhiriéndose al principio de que el reconocimiento de los tipos de vegetación debe basarse en la composición florística total, los ecólogos del DCR-DNH emplean el análisis de conglomerados para generar clasificaciones. El análisis de conglomerados es un método de clasificación numérica que evalúa la similitud de muestras cuantitativas y, a través de un proceso estadístico interactivo, fusiona en conglomerados aquellas muestras que son más similares. En la ecología de la vegetación se han utilizado diferentes tipos de análisis de conglomerados: los ecólogos del DCR-DNH utilizan el análisis de conglomerados aglomerantes-jerárquicos, que comienza con cada muestra en su propio grupo y las fusiona progresivamente en grupos más grandes. Los resultados se muestran como un dendrograma, un gráfico en forma de árbol que representa la resolución de los grupos fusionados progresivamente. A modo de ejemplo, este dendrograma muestra la agrupación en clústeres de un conjunto de datos de 72parcelas y la identificación de cuatro grupos principales que podrían representar tipos de vegetación.
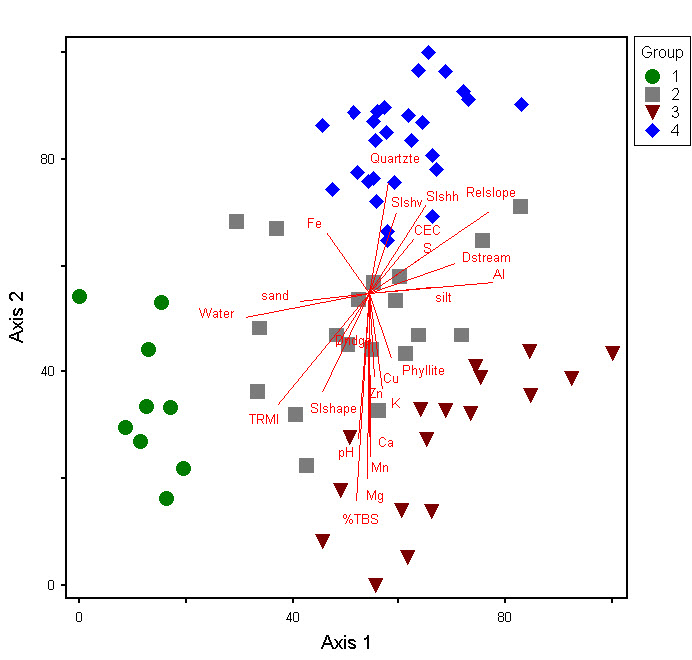
Posteriormente, se realiza la ordenación para evaluar la clasificación e identificar los gradientes ambientales y las condiciones del sitio más fuertemente asociados con la variación en la composición de especies. La ordenación es una técnica multivariada que organiza las muestras de vegetación en relación entre sí en función de la similitud de la composición y la abundancia relativa de especies. Los procedimientos de ordenación resumen datos multidimensionales en un sistema de coordenadas reducido, extrayendo aquellos ejes que explican la mayor variación en los datos. Los ecólogos del DCR-DNH utilizan el escalamiento multidimensional no métrico (NMDS), que se basa en el análisis de gradiente indirecto que maximiza, en la medida de lo posible, la correlación de orden de clasificación (es decir, no paramétrica) entre la disimilitud entre muestras y la distancia entre muestras en el espacio de ordenación. Los resultados de los análisis de ordenación se representan mediante diagramas, en los que cada punto representa una gráfica y la distancia entre puntos indica aproximadamente el grado de similitud compositiva. Las correlaciones estadísticamente significativas entre las variables ambientales medidas y las coordenadas de la muestra en cada eje se pueden trazar como vectores y superponer en el diagrama. La dirección de un vector indica la dirección de la correlación máxima a través del espacio de ordenación, mientras que las longitudes de las líneas vectoriales están determinadas por la fuerza de la correlación. Este diagrama muestra una ordenación bidimensional del mismo conjunto de datos que se utiliza para ilustrar el análisis de clústeres. Los símbolos indican los cuatro grupos identificados en el dendrograma y se trazan gradientes ambientales significativos.
Tanto el análisis de conglomerados como la ordenación se implementan en PC-ORD (versión 6; McCune y Mefford 1999-2011). Una vez que se identifican los posibles tipos de vegetación, se calculan varios estadísticos resumidos para evaluar la consistencia y el carácter distintivo del tipo y para ayudar a seleccionar los taxones nominales. Los valores específicos de la especie para la constancia (la proporción de parcelas asignadas a un tipo de vegetación en la que se encuentra una especie), la fidelidad (el grado en que una especie está restringida a un tipo particular) y la cobertura media identifican las especies más características y dominantes para cada tipo.
Nomenclatura de la comunidad
La nomenclatura de los tipos de comunidades es similar a los estándares adoptados para el USNVC, que utiliza los nombres científicos de hasta cinco especies características. Aunque no pueden servir como sustitutos completos de descripciones detalladas, los nombres de los tipos de comunidades se construyen para facilitar tanto la distinción entre los tipos como la identificación fácil de ellos en el campo. Los nombres del estado de Virginia utilizan hasta seis especies características. Como regla general, las especies se enumeran en orden descendente de importancia y posición estructural (es decir, las especies del sotobosque se enumeran primero, seguidas de las especies del sotobosque, luego las hierbas y los arbustos bajos). Las especies utilizadas como nominales tienen una alta constancia (generalmente > 60%, pero ocasionalmente > 50% si son especialmente diagnósticas). Las especies nominales en el mismo estrato están separadas por un guión (-), mientras que los diferentes estratos están separados por una barra (/). Las especies enumeradas entre paréntesis son menos constantes, pero localmente importantes, en un tipo. Cuando dos especies se enumeran entre paréntesis, significa que una o ambas pueden ser importantes en un rodal determinado. La fisonomía típica (es decir, bosque, arboleda, matorrales, etc.) y, en el caso de las comunidades de humedales de marea, el régimen hidrológico se incluyen al final del nombre formal del tipo de comunidad. Un equivalente de nombre común no es una traducción estricta de los nombres latinos de especies nominales, sino que generalmente se refiere al nombre del grupo ecológico y contiene un modificador composicional o geográfico. A modo de ejemplo,
Zizania aquatica - Pontederia cordata - Peltandra virginica - Persicaria punctata Vegetación herbácea de marea
Marisma de marea de agua dulce (arroz salvaje - tipo de hierbas mixtas)Acer rubrum - Fraxinus americana - Fraxinus nigra - (Betula alleghaniensis) / Veratrum viride - Carex bromoides - Bosque
Pantano de filtración básico de los Apalaches centrales

{kind=link}
{kind=link}